Written in 1787, ratified in 1788, and in operation since 1789, the United States Constitution is the world’s longest surviving written charter of government cite. I downloaded the full text of the US constitution and its 27 amendments from here and conducted a simple analysis on its evolution.
Who is more important ? President, Congress, or Senate ?
The original version of the constitution has 4254 words. The word ‘president’ appreared for 32 times, more than ‘congress’ (27) and ‘senate’ (17). Even from the term frequencies we can infer the rank of importance as
+ President > Congress > Senate
Use the onlne tool develped by Jason Davies we get the following word cloud.

This figure gives a very intuitive image of the importance rank.
The stablility of the US constitution
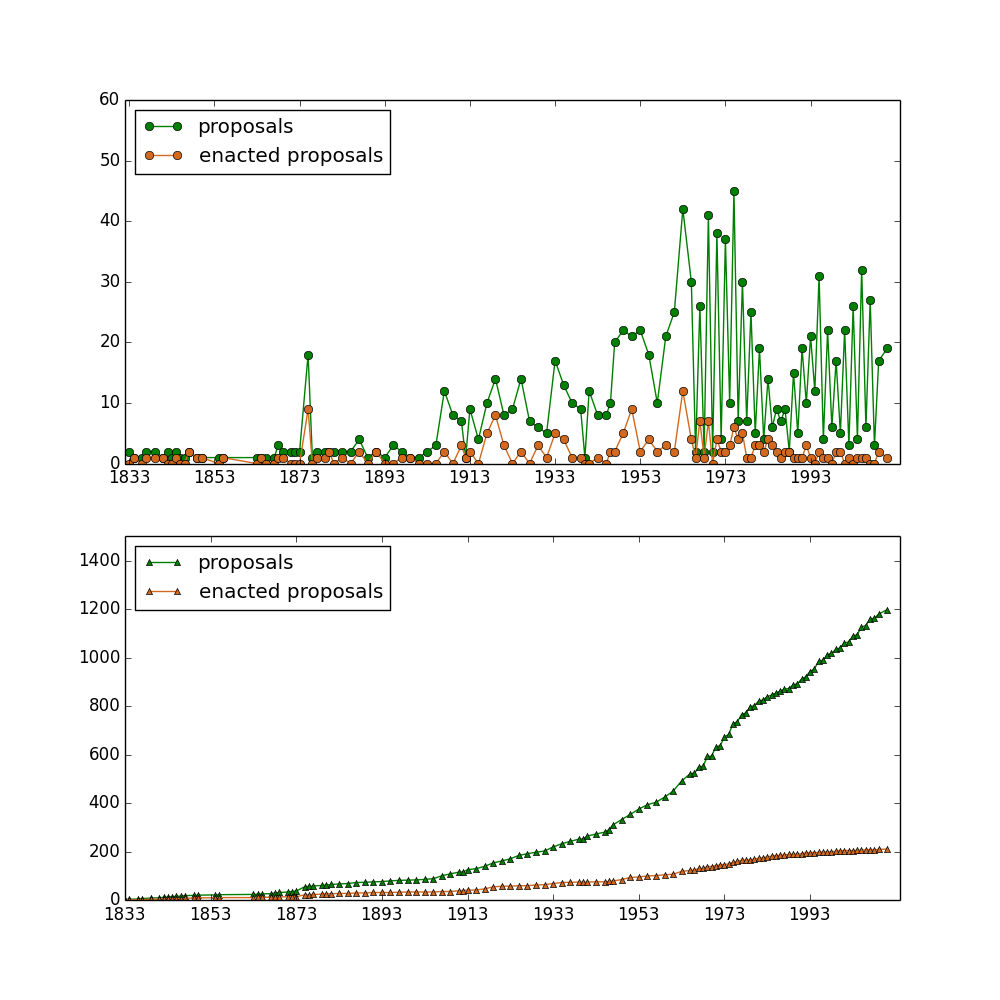
The probability of an amendment being accept: 0.2%
Approximately 11,539 measures have been proposed to amend the Constitution in more than two hundred years (1789 ~ 2012), but we know that only 27 amendments were accepted soruce. So the chance of a proposal to amend the consitution being accepted is 0.2%. Considering the dramatic change of our society in the past two hundred years, this incredibly low rate reflects that the consitution is very stable.
I scrapped this page and plotted the following figure to show the growth of proposals, both the original ones and the enacted ones. It should be noted that the enacted proposals may not pass the voting, so its number is larger than 27.
The average waiting time before an amendment being accept: 20 months
Another realted question is, how long will it take to pass a amendment? From here we obtained the processing time of each amendaments and derived the following plot:
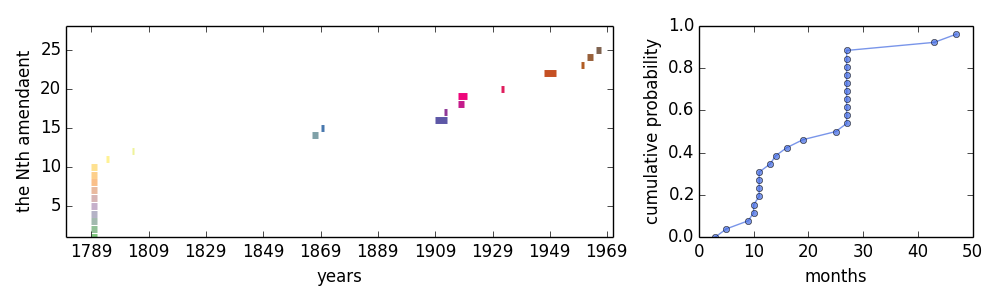
The average time needed for passing an amendment is 20.3 months. No very long, right ? But we have not counted the 27th amendment in. This amendment, which prohibits any law that increases or decreases the salary of members of Congress from taking effect until the start of the next set of terms of office for Representatives, was submitted on 1789 and became part of the constitution in 1992, so the duration was 202 years, 7 months and 12 days ! This is obviously an outlier and thus we did not included it in the analysis of the durations - if we included this case, the average waiting time will increase to 110 months.
The 26th amendment, proposed on March 1971 and enacted in July 1971, is the amendment approved most quickly (3 months). It prohibits the states and the federal government from setting a voting age higher than eighteen. Looks like people arrive at a consensus on this case very easily.
The novelty of the amendents
We are curious to find out how the amendments are different from the original version of consitition, i.e., how novel are these revisions. Among various defnition of novelty/dissimilarity between text, we adopt the “information cost of encoding”, which comes from Elements of Information Theory and was used impressively by Brendan J. Frey and Delbert Dueck in their 2007 Science [paper] (http://www.sciencemag.org/content/315/5814/972.full) to identify “representative sentences”:
"The similarity of sentence i to sentence k was set to the negative sum of the
information-theoretic costs of encoding every word in sentence i using the words
in sentence k and a dictionary of all words in the manuscript. For each word in
sentence i, if the word matched a word in sentence k, the coding cost for the word
was set to the neg- ative logarithm of the number of words in sentence k (the cost
of coding the index of the matched word), and otherwise it was set to the negative
logarithm of the number of words in the manuscript dictionary (the cost of coding
the index of the word in the manuscript dictionary). A word was considered to match
another word if either word was a substring of the other."
The above defnition give the following codes:
def words(text): return re.findall('[a-z]+', text.lower())
def cost(i,k):
i = words(i)
k = words(k)
D = set(i+k)
c = 0
for j in i:
if j in k:
c+=np.log2(len(k))
else:
c+=np.log2(len(D))
return c
As we are measuring the novelty/dissimilarity and not similarity between text, we remove the negative symbol in Frey and Dueck’s definition. According to the revised formula, the distance from “I love you” to “I hate you” is 5.2, and the distance from “I love him” to “I hate you” is 6.2. Seems to be consistent with our intuitive feeling.
Another option is the consine similarity, which is used extensibely in the industry to measure the similarity between posts (e.g., answer recommendation in Q&A communities). As we are talking about novelty, we inverse it by dividing 1 by the cosine similarity. Here is a naive version of the function:
def cosine(i, k):
i,k = map(lambda x:Counter(words(x)), [i,k])
q = set(i.keys()) & set(k.keys())
a = sum([i[x] * k[x] for x in q])
s1 = sum([i[x]**2 for x in i])
s2 = sum([k[x]**2 for x in k])
b = s1**0.5 * s2**0.5
if not b:
return 0.0
else:
return b / float(a)
The consine similarity between “I love you” and “I hate you” is 1.5, and that between “I love him” to “I hate you” is 3.
In the following plot we show the novelty of amendments compared to the original constitution. These two novelty measurements are very different. Information cost generally increases with the length of text but the cosine-similarity based novelty does not. Maybe the cosine-similarity based novelty is a better indicator because it provides new information that does not given by the information cost/text length.

According to the third plot above, the 8th amendament is very novel/unsimilar to the original version of the consitution (denoted by index “0”). This is the section of the Bill of Rights that states that that punishments must be fair, cannot be cruel, and that fines that are extraordinarily large cannot be set. Why this amendment very novel is a issue worth further exploration.
Other things worth exploartion
In more comprehensive analyis, the frequencies of the words should be cosidered. In other words, we shall weight the words by their frequencies and cosider tf-idf cosine similarity.
In future, we can consider a “law correction” tool for lawyers as the popular spell correction tools, to dispaly the revisions of laws using tree or wordtree, or measure the increase of information in law evolution by KL distance or information-thoretic cost.
Reference
My idea for analyzing the evolution of rules is inspired by the following interesting book: The Dynamics of Rules.
supplementary materials: Python codes
import numpy as np
import urllib2
import matplotlib.pyplot as plt
import re
from bs4 import BeautifulSoup
import matplotlib.cm as cm
import matplotlib.gridspec as gridspec
# get universal English word frequency for comparison
def Fre(list):
D = collections.defaultdict(lambda: 1)
for i in list:
D[i] += 1
return D
def words(text): return re.findall('[a-z]+', text.lower())
W = urllib2.urlopen('http://norvig.com/big.txt')
W = Fre(words(W.read()))
# get the text of us constitution and its 27 amendents
t = urllib2.urlopen('http://www.usconstitution.net/const.txt')
t=re.sub('\n','',t.read().split(']')[1])
tlist = t.split('Amendment ')
tlist[:2] = [''.join(tlist[:2])]
#nlist = [''.join(tlist[:i]) for i in range(1,len(tlist)+1)]
# the frequency of president, congress, and senate
te=words(tlist[0])
c=Counter(te)
c['president'],c['congress'],c['senate']
# get the statistics of proposals
html = urllib2.urlopen('http://www.state.me.us/legis/lawlib/constleg1820_.htm').read()
a=r'</tr>'
b=r'<td valign="top" class="smalllinksblack">'
c=r'</td>'
d = html.split(a)[2:-4]
e = [i.split(b) for i in d]
#[item for sublist in l for item in sublist]
f = [i.split(c)[0] for j in e for i in j]
f = np.array(f).reshape(len(f)/6,6)[:,1:-1]
data = [(int(i[0][:4]),int(i[-1][:7]=='Enacted')) for i in f if i[0][:4].isdigit()]
data = np.array(data)
cy={}#year:[N of proposal, N of enacted proposal]
for i in data:
year=i[0]
if year not in cy:
cy[year]=[1,i[1]]
else:
cy[year]=[cy[year][0]+1,cy[year][1]+i[1]]
# plot the growth of proposals and amendments
ps=[i[0] for i in cy.values()]
cs=[i[1] for i in cy.values()]
fig = plt.figure(figsize=(10, 10),facecolor='white')
ax = fig.add_subplot(211)
ax.plot(cy.keys(),ps,color='green',linestyle='-',marker='o',label='proposals')
ax.plot(cy.keys(),cs,color='chocolate',linestyle='-',marker='o',label='enacted proposals')
ax.set_xlim(1832,2014)
ax.set_ylim(0,60)
ax.set_xticks(np.arange(min(cy.keys()), max(cy.keys()), 20))
plt.legend(loc='upper left')
ax = fig.add_subplot(212)
ax.plot(cy.keys(),np.cumsum(ps),color='green',linestyle='-',\
markersize=5,marker='^',label='proposals')
ax.plot(cy.keys(),np.cumsum(cs),color='chocolate',markersize=5,\
linestyle='-',marker='^',label='enacted proposals')
plt.xlim(1833,2014)
ax.set_ylim(0,1500)
ax.set_xticks(np.arange(min(cy.keys()), max(cy.keys()), 20))
plt.legend(loc='upper left')
plt.savefig('/Users/csid/Documents/githublog/csidsocialmedia.github.io/media/files/\
2014-03-25-The-Evolution-of-the-US-Constitution/growth.png',transparent = True)
plt.show()
#plot the duration of enaction
start = [1789,1789,1789,1789,1789,1789,1789,1789,1789,1789,1794,1803,1865,1866,1869,
1909,1912,1917,1917,1932,1933,1947,1960,1962,1965,1971]
end = [1791,1791,1791,1791,1791,1791,1791,1791,1791,1791,1795,1804,1865,1868,1870,
1913,1913,1919,1920,1933,1933,1951,1961,1964,1967,1971]
duration = [27,27,27,27,27,27,27,27,27,27,11,5,10,25,11,43,11,13,14,11,10,47,9,16,19,3]
exception = [1789,1992,2432]
ys=[1788,1791,1791,1791,1791,1791,1791,1791,1791,1791,1791,1798,1804,1865,1868,1870,1913,1913,1919,
1920,1933,1933,1951,1961,1964,1967,1971,1992]
fig = plt.figure(figsize=(10, 3),facecolor='white')
gs = gridspec.GridSpec(1, 2,width_ratios=[2,1])
ax1 = plt.subplot(gs[0])
cmap = cm.get_cmap('Accent', len(start))
for i in range(len(start)):
ax1.hlines(i+1, start[i],end[i],color=cmap(i),linewidth=5)
ax1.set_xlim(1780,1971)
ax1.set_ylim(1,28)
ax1.set_xticks(np.arange(min(start), max(end), 20))
ax1.set_xlabel('years')
ax1.set_ylabel('the Nth amendaent')
ax2 = plt.subplot(gs[1])
ax2.plot(sorted(duration),np.array(range(len(duration)))/(len(duration)+0.0),
color='RoyalBlue',markersize=5,alpha=0.7,linestyle='-',marker='o')
ax2.set_xlabel('months')
ax2.set_ylabel('cumulative probability')
plt.tight_layout()
plt.savefig('/Users/csid/Documents/githublog/csidsocialmedia.github.io/media/files/\
2014-03-25-The-Evolution-of-the-US-Constitution/duration.png',transparent = True)
plt.show()
# function to calculate the information cost of of encoding every word in text i
# using the words in sentence k and a dictionary of all words.
# ref: http://www.sciencemag.org/content/suppl/2007/01/08/1136800.DC1/Frey.SOM.pdf
def cost(i,k):
i = words(i)
k = words(k)
D = set(i+k)
c = 0
for j in i:
if j in k:
c+=np.log2(len(k))
else:
c+=np.log2(len(D))
return c
def cosine(i, k):
i,k = map(lambda x:Counter(words(x)), [i,k])
q = set(i.keys()) & set(k.keys())
a = sum([i[x] * k[x] for x in q])
s1 = sum([i[x]**2 for x in i])
s2 = sum([k[x]**2 for x in k])
b = s1**0.5 * s2**0.5
if not b:
return 0.0
else:
return b/float(a)
# function to measure he Kullback-Leibler Distance
def KLD(text):
wlist = words(text)
C = Fre(wlist)
KL=0
M = sum(C.values())
N = sum(W.values())
for i in wlist:
pi = (C[i]+0.0)/M
qi = (W[i]+0.0)/N
di = pi*np.log2((pi+0.0)/qi)
KL += di
return KL
# plot the novelty of each amendments
ls = map(lambda x:len(words(x)),tlist)
ks = map(lambda x:cost(x,tlist[0]),tlist)
js = map(lambda x:cosine(x,tlist[0]),tlist)
d = np.array(zip(ys,ls,ks,js))
fig = plt.figure(figsize=(12, 4),facecolor='white')
ax = fig.add_subplot(1,3,1)
ax.plot(d[:,0],d[:,2],color='RoyalBlue',marker='o',linestyle='-',label='information cost')
ax.plot(d[:,0],d[:,3],color='ForestGreen',marker='^',linestyle='-',label='revsered cosine similarity')
plt.legend(loc='upper left',fontsize=10)
#ax.set_xscale('log')
ax.set_yscale('log')
ax.set_xlabel('years',size=14)
ax.set_ylabel('Novelty',size=14)
ax = fig.add_subplot(1,3,2)
ax.plot(d[:,1],d[:,2],color='RoyalBlue',marker='o',linestyle='',label='information cost')
ax.plot(d[:,1],d[:,3],color='ForestGreen',marker='^',linestyle='',label='revsered cosine similarity')
plt.legend(loc='upper left',fontsize=10)
ax.set_xscale('log')
ax.set_yscale('log')
ax.set_xlabel('N of words',size=14)
ax.set_ylabel('Novelty',size=14)
ax = fig.add_subplot(1,3,3)
ax.plot(d[:,2],d[:,3],marker='o',color='orange',linestyle='',alpha=0.3)
for i in range(len(d)):
ax.text(d[i,2],d[i,3],str(i),alpha=0.7)
ax.set_xscale('log')
#ax.set_yscale('log')
ax.set_xlabel('information cost',size=14)
ax.set_ylabel('revsered cosine similarity',size=14)
plt.tight_layout()
plt.savefig('/Users/csid/Documents/githublog/csidsocialmedia.github.io/media/files/\
2014-03-25-The-Evolution-of-the-US-Constitution/novelty.png',transparent = True)
plt.show()